개요
스프링 배치(Spring Batch)는 대량의 데이터를 처리하는 데 특화된 배치 프로세싱 프레임워크이다.
데이터 읽기, 처리, 쓰기 과정을 간단하게 설정할 수 있게 설계되어 있다.
프로젝트 생성
IntelliJ를 사용한 프로젝트 생성 방법이다.
JPA, H2 Database, Spring Batch를 추가하여 프로젝트를 생성한다.


// build.gradle
plugins {
id 'java'
id 'org.springframework.boot' version '3.4.0'
id 'io.spring.dependency-management' version '1.1.6'
}
group = 'com.temp'
version = '0.0.1-SNAPSHOT'
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-batch'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.h2database:h2'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.batch:spring-batch-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
tasks.named('test') {
useJUnitPlatform()
}
구조
Spring Batch는 Job과 Step의 조합으로 구성된다.
JOB
Step 인스턴스들의 모임으로, 여러 Step 인스턴스들을 조합하여 하나의 작업을 만들고
재시작 여부와 같은 전역적인 속성들을 설정할 수 있다.
Step
배치 작업의 독립적이고 순차적인 단계를 캡슐화하는 도메인 객체이다.
모든 Job은 모두 하나 이상의 Step으로 구성된다.
Step은 실제 배치 처리를 정의하고 제어하는데 필요한 모든 정보가 포함된다.
Step의 구현
Step을 구현하는 방식은 크게 두 가지로 나뉜다.
1. Tasklet을 통한 구현

✓ Step이 중지될 때까지 execute 메서드가 계속 반복해서 수행되고, 수행될 때마다 독립적인 트랙잭션이 얻어짐
✓ 초기화, 저장 프로시저 실행, 알림 전송과 같은 Job에서 일반적으로 사용
✓ 계속 진행할지 끝낼지 두 가지 경우만 제공
✓ 데이터 처리 과정이 tasklet 안에서 한 번에 이루어지고, 배치 처리 과정이 쉬운 경우 쉽게 사용(대용량 데이터의 경우 더 복잡해짐)
2. Chunk 기반 구현

✓ 한 번에 하나씩 데이터(row)를 읽어 Chunk라는 덩어리를 만든 뒤, Chunk 단위로 트랜잭션을 다룸
✓ Chunk 단위로 트랜잭션을 수행하기 때문에 실패할 경우엔 해당 Chunk만큼만 롤백이 되고, 이전에 커밋된 트랜잭션 범위까지는 반영됨
✓ 대용량 데이터를 처리할 경우 사용됨
✓ Chunk 기반 Step은 ItemReader, ItemProcessor, ItemWriter라는 3가지 주요 부분으로 구성
ItemReader, ItemProcessor에서 데이터는 1건씩 처리되고, ItemWriter에선 Chunk 단위로 한 번에 처리
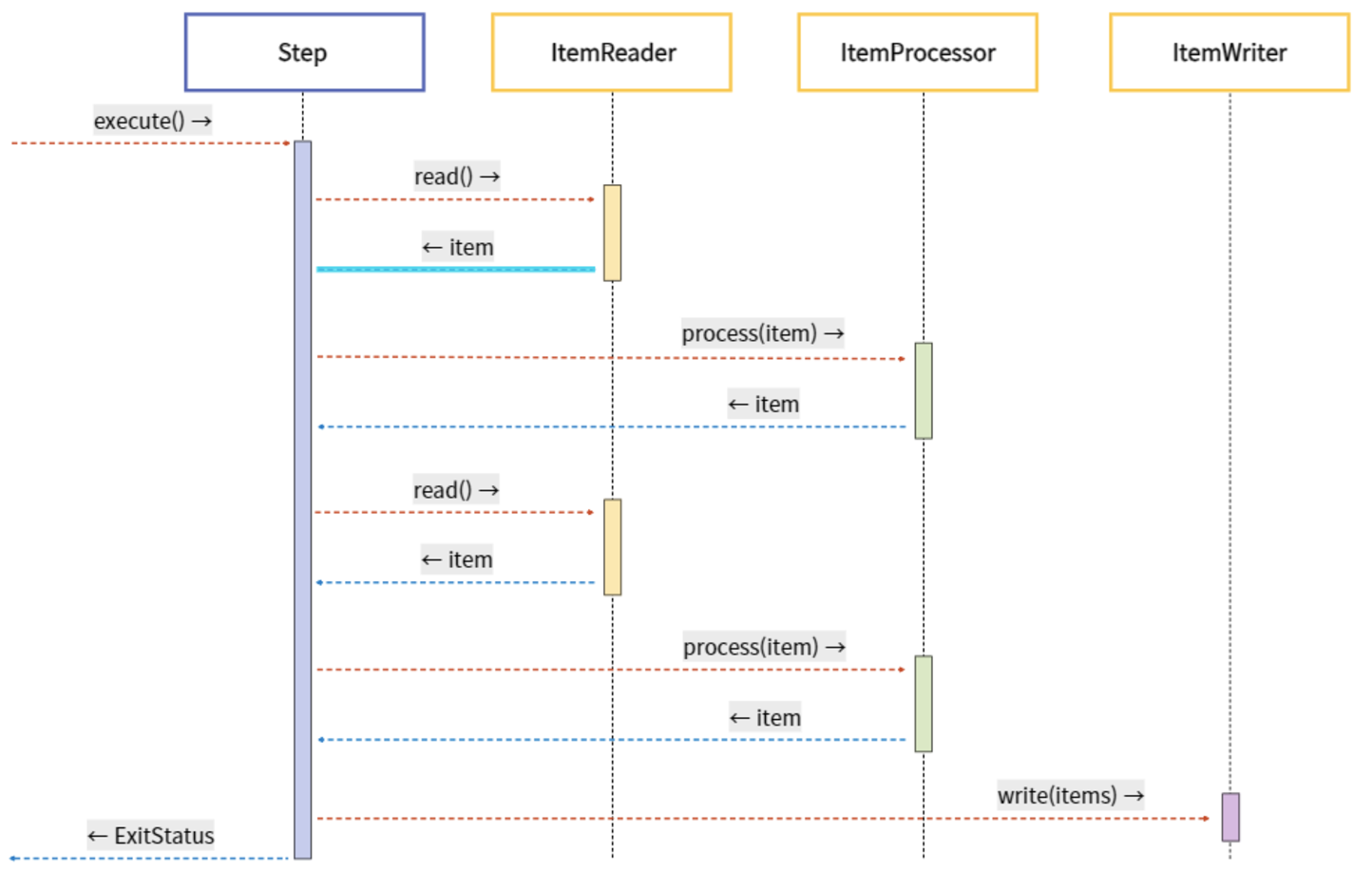
ItemReader
Step(Database)에서 배치 처리할 Item을 읽어오는 역할
ItemReader에 대한 다양한 인터페이스가 존재하고, 다양한 방법으로 Item을 읽어올 수 있음
ItemProcessor
Reader로 읽어온 Item을 가공/처리하는 역할
배치를 처리하는데 필수 요소는 아님
Item을 필터 도중 Null로 리턴하면, 그 Item은 Writer로 전달되지 못함(값이 있는 Item들만 Writer로 전달됨)
ItemWriter
Processor로 가공/처리된 아이템들을(List<Item>) Database에 저장하는 역할
처리 결과물에 따라 Insert / Update / Queue를 사용하면 Send가 될 수도 있음
ItemWriter에 대한 다양한 인터페이스가 존재
기본적으로 Item들은 List단위로 처리되며, 그 List는 Chunk 단위로 처리됨
Tasklet 예제코드
package com.aton.stockbatch.config;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Bean
public Job exampleJob(JobRepository jobRepository, Step exampleStep) {
return new JobBuilder("exampleJob", jobRepository)
.start(exampleStep)
.build();
}
@Bean
public Step exampleStep(JobRepository jobRepository, Tasklet exampleTasklet, PlatformTransactionManager transactionManager) {
return new StepBuilder("exampleStep", jobRepository)
.tasklet(exampleTasklet, transactionManager)
.build();
}
@Bean
public Tasklet exampleTasklet() {
return (contribution, chunkContext) -> {
System.out.println("Hello! This is Spring Batch Practice!!");
return RepeatStatus.FINISHED;
};
}
}
동작 순서
(contribution, chunkContext) -> { ... }Tasklet의 execute 메서드 구현이다.
contribution: Step의 상태 및 실행 컨텍스트를 나타낸다.
chunkContext: Chunk 처리와 관련된 추가 정보를 제공한다.
// "Hello! This is Spring Batch Practice!!"라는 메시지를 출력한다.
System.out.println("Hello! This is Spring Batch Practice!!");
// 작업이 완료되었고, 반복이 필요하지 않다는 것을 의미한다.
return RepeatStatus.FINISHED;
Chunk 기반 예제코드
package com.aton.stockbatch.config;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.support.ListItemReader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
import java.util.Arrays;
import java.util.List;
@Configuration
@EnableBatchProcessing
public class ChunkBasedBatchConfig {
@Bean
public Job chunkJob(JobRepository jobRepository, Step chunkStep) {
return new JobBuilder("chunkJob", jobRepository)
.start(chunkStep)
.build();
}
@Bean
public Step chunkStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ItemReader<String> itemReader,
ItemProcessor<String, String> itemProcessor,
ItemWriter<String> itemWriter) {
return new StepBuilder("chunkStep", jobRepository)
.<String, String>chunk(3) // Chunk 크기 설정
.reader(itemReader)
.processor(itemProcessor)
.writer(itemWriter)
.transactionManager(transactionManager)
.build();
}
@Bean
public ItemReader<String> itemReader() {
List<String> data = Arrays.asList("Item1", "Item2", "Item3", "Item4", "Item5");
return new ListItemReader<>(data);
}
@Bean
public ItemProcessor<String, String> itemProcessor() {
return item -> "Processed " + item;
}
@Bean
public ItemWriter<String> itemWriter() {
return items -> items.forEach(item -> System.out.println("Writing item: " + item));
}
}
동작 순서
1. Chunk의 크기를 3으로 설정하였다. ItemReader와 ItemProcessor는 3개씩 데이터를 읽고 처리한 뒤, Writer로 전달한다.
2. ItemReader에서 5개의 데이터를 생성하고 3개, 2개씩 읽는다.
3. ItemProcessor에서 데이터 앞에 "Processed" 를 붙인다. 5개의 데이터를 3개, 2개씩 처리한다.
4. Writer에서 Chunk 별로 처리한다. "Writing item : itemN"을 출력한다.
문의사항이나 피드백은 댓글로 남겨주세요.
'프로그래밍 언어 > JAVA, SPRING' 카테고리의 다른 글
| [SPRING BOOT] 멀티모듈 프로젝트 설계하기 (1) | 2024.11.26 |
|---|---|
| [SPRING BOOT] WebSocket과 Redis를 활용한 실시간 채팅 시스템 구축하기 (0) | 2024.11.26 |
| [SPRING BOOT] CORS 에러와 DELETE요청 해결하기 (0) | 2024.11.26 |
| [SPRING BOOT] UnrecognizedPropertyException 해결하기 (0) | 2024.11.26 |
| [JAVA] Exception Handling (0) | 2024.07.22 |